ОПРЕДЕЛЕНИЕ ПОТРЕБНОСТИ ПРЕДПРИЯТИЯ В ТОПЛИВЕ И ЭНЕРГИИ
Под экономическим прогнозированием будем понимать получение сведений о некотором показателе, характеризующем поведение объекта или явления в будущем, на основе математико-статистической модели. Конечный результат этого процесса называется прогнозом. В связи со стохастическим характером математико-статистических моделей прогнозируемый показатель является случайной величиной с известным законом распределения вероятностей. Экономическое прогнозирование следует рассматривать как вспомогательный инструмент планирования на этапе разработки многовариантных проектов плана. Следует отметить, что методы прогнозирования потребности в топливе и энергии на уровне предприятия пока применяются редко. В то же время использование этих методов расширяет возможности и повышает точность плановых расчетов.
Прогнозирование не подменяет планирования и его методов. Разработка прогнозов позволяет, однако, получить информацию, повышающую точность и достоверность планирования. При этом методы математико-статистического прогнозирования дают возможность оценить точность предсказания в будущем. Оценка точности прогнозов может проводиться двумя путями: на основе расчета средних ошибок прогнозирования (т. е. ожидаемых отклонений фактических значений прогнозируемых величин от их прогнозов); определением доверительного интервала прогноза, в который попадает фактическое значение прогнозируемой величины.
Рассмотрим основные условий разработки достоверных прогнозов, не затрагивая самих методов прогнозирования, изложение которых можно найти в специальной литературе [42—44 и др.]. Это необходимо в связи с тем, что некритичные попытки использования математических методов в прогнозировании приводят к отрицательным выводам о возможности применения моделей прогнозирования в плановых расчетах. Эффективность методов прогнозирования всецело зависит именно от правильного выбора условий прогноза, а не от используемой техники расчетов.
В соответствии с теорией и практикой прогнозирования можно определить следующие основные требования, обязательные при разработке экономических прогнозов: выбор класса и типа модели прогнозирования; анализ экзогенных факторов и оценка их значений в прогнозируемом периоде; сохранение стабильности структурных параметров модели во времени; стабильность распределения случайного члена; допустимость экстраполяции модели за пределы известной выборки; оценка эффективности выбранных моделей прогнозирования; определение допустимого горизонта прогноза. Рассмотрим каждое из этих требований более подробно.
Выбор математико-статистической модели для целей прогнозирования зависит от характера прогнозируемого явления, исследуемого статистического материала, требуемой точности прогнозов, а также многих других факторов, связанных с конкретными условиями прогнозирования. Современная теория и практика прогнозирования выделяет, по крайней мере, три класса математико-статистических моделей; причинно-следственных связей; тенденций развития; адаптивные модели прогнозирования.
Как правило, исходным моментом всей работы по прогнозированию является построение модели причинно-следственных связей. В таких моделях поведение эндогенной переменной зависит от комбинации ряда факторов *. Для моделей этого класса обычно легко рассчитать показатель точности прогнозирования, например среднюю ошибку. Однако разработка такой модели
*В таких случаях обычно значения экзогенных факторов определяются путем экстраполяции их трендов, однако такой метод не всегда гарантирует правильные решения.
(в особенности модели, гарантирующей низкий уровень случайных колебаний прогноза) не всегда является возможной прежде всего потому, что могут отсутствовать необходимые статистические данные. Прогнозирование на основе этих моделей может быть затруднено и в связи с трудностями достоверной оценки значений отдельных факторов в прогнозируемом периоде, особенно когда эти факторы не являются плановыми показателями*. В экономике постоянно происходят изменения (в структуре. продукции, технико-экономических показателях, организации и управлении и т. п.), что приводит к нарушению стабильности модели во времени. Это означает, что по мере удаления от базового периода, которому соответствуют данные начальной выборки, можно ожидать потерю способности параметров модели объективно отражать связи между переменной и факторами. В результате использование моделей причинно-следственных связей на практике не всегда оправданно и даже возможно.*В случае модели причинно-следственных связей обычно используется линейная форма, дающая удовлетворительную аппроксимацию; в моделях тенденций развития линейная форма является далеко не единственной.
Значительно проще оказывается расчет прогнозов на основе моделей тенденций развития, в которых имеется единственный фактор — время. Выбирая этот тип моделей, удается обойти первые две трудности, присущее моделям причинно-следственных связей. Однако возникает новая проблема — выбор вида аналитической зависимости между эндогенной переменной и временем*. Модели тенденций развития обычно дают высокую точность прогнозов, особенно в условиях, когда все факторы, влияющие на эндогенную переменную, имеют явно выраженный тренд, а отклонения факторов в прогнозируемом периоде от их трендов невелики. Модели причинно-следственных связей целесообразно использовать в явлениях со значительными изменениями; когда же явления развиваются систематически и регулярно, следует применять более простые модели тенденций развития.*Среди известных методов адаптивного прогнозирования следует отметить методы: экспоненциального сглаживания спектральных функций, линейных фильтров и многие другие. Все они практически освоены в различной степени, по некоторым имеются лишь теоретические обоснования.
Оба класса моделей имеют существенный недостаток из-за изменения во времени их параметров. При этом оно возрастает пропорционально интервалу (Т—tо) где Т — горизонт прогнозирования. Использование таких моделей приводит к появлению существенных систематических ошибок в результатах прогноза. Для их преодоления периодически переоцениваются структурные параметры моделей при одновременном отбрасывании наблюдений, относящихся к дальним периодам. Не исключена возможность внедрения поправок на систематическую ошибку модели по выборке, составленной из отклонений фактических значений от расчетных. Однако в этом случае требуется достаточно большое число наблюдений и более целесообразной, по-видимому, является периодическая переоценка параметров основной модели, чем расчет поправок на систематические отклонения.Наиболее перспективным способом в случае частных и нерегулярных колебаний в развитии явления можно считать применение моделей, основанных на идеях самостоятельной адаптации параметров к ожидаемым изменениям в прогнозируемом периоде.
Класс адаптивных моделей в настоящее время довольно широк. Их характерным элементом является отсутствие стабильности структурных параметров. Модели допускают изменение тренда, характера периодических колебаний, а также характеристик распределения случайного члена. Изменения могут быть частными и нерегулярными, при этом соответствующий механизм адаптации должен по возможности быстро исключать прежние закономерности развития и приспосабливаться к новым. В зависимости от конкретного вида моделей адаптивного прогнозирования применяются различные методы построения прогнозов*.
*Эта процедура может быть формализована, например, путем использования методов имитации (метод Монте-Карло).
Важным качеством моделей прогнозирования этого класса является возможность обеспечения стационарности распределения ошибок прогнозирования. Это означает, что наблюдаемые в прошлом характеристики распределения сохраняются и в будущем. На этом положении основана оценка точности прогнозов, т. е. предвидение возможных ошибок прогнозов до фактической реализации прогнозируемой величины. Тем самым (несмотря на отсутствие регулярности в развитии явления) сохраняется основное положение математического прогнозирования — возможность оценки точности прогноза. Это весьма важно, так как можно проводить сопоставление различных моделей и выбор наилучшей из них, что обеспечивает минимальные ошибки прогнозирования.Модели адаптивного прогнозирования наиболее пригодны для построения краткосрочных прогнозов показателей, подверженных сезонным и многолетним колебаниям. Это, конечно, не означает, что модели причинно- следственных связей и тенденций развития потеряют свое значение. Существует довольно широкая область явлений, отличающихся регулярностью развития, для которых эти методы дают более приемлемые результаты.
Необходимость повышения надежности прогнозов делает чрезвычайно актуальным исследование проблем выбора формы связи. В экономических исследованиях обычно рассматривается определенный стандартный набор кривых. Для измерения дисперсии данных, поглощаемой избранной формой связи, в теоретической статистике применяется коэффициент корреляции. Этот формальный показатель имеет ряд недостатков при использовании его в качестве критерия выбора той или иной кривой из рассматриваемого в задаче набора. Хотя истинная форма связи всегда обеспечивает минимальное отклонение от наблюдаемых данных, минимальные отклонения не всегда свидетельствуют об истинности избранной формы связи.
Необходимо отметить, что с точки зрения приведенных выше критериев один и тот же эмпирический материал может быть описан различными формами связи, т. е. имеет место явление гомоморфизма. Проблема разрешения неопределенности гомоморфизма требует более глубокого проникновения в сущность явления, представленного эмпирическими данными. В настоящее время эта неформальная задача решается интуитивно. Однако имеются пути достаточно строго математического обоснования выбора типа кривой на основе использования эвристического аппарата аналитической геометрии [45].
Выбирая тип модели прогнозирования и форму связи, следует обращать особое внимание на содержательную сторону процесса идентификации явления. Формальные процедуры позволяют выбрать модель, наиболее стабильную во времени, и по ней оценить возможный интервал прогнозирования.
Выбор экзогенных факторов и оценка их значений в прогнозируемом периоде наиболее ответственные этапы работы по построению математико-статистических моделей. От того, какие именно признаки будут использованы для описания объекта, зависит возможность построения адекватной модели. Эта стадия работы не имеет формального алгоритмического характера Она зависит от профессионального знания объекта, опыта предыдущих исследований, интуиции исследователя.
При некорректном решении задачи возникают различные методологические трудности. Одна из них связана с явлением мультиколлинеарности, т. е. наличием сильной корреляции между всеми или некоторыми экзогенными переменными, входящими в модель. Мультиколлинеарность затрудняет проведение математикостатистического анализа результатов моделирования. Во-первых, усложняется процесс выделения наиболее существенных факторов. Во-вторых, искажается смысл параметров модели при их экономической интерпретации. В-третьих, возникают осложнения вычислительного характера, так как появляется эффект слабой обусловленности матрицы системы нормальных уравнений. Это приводит к получению неопределенного множества оценок коэффициента регрессии.
Явление мультиколлинеарности выявляется вычислением матрицы парных коэффициентов корреляции между экзогенными переменными. На практике считают, что две величины коллинеарны, если коэффициент корреляции между ними по абсолютной величине больше 0,8 [46]. Существуют и другие методы определения мультиколлинеарности, приводимые в работах [47, 48 и Др.].
Меры по устранению мультиколлинеарности неразрывно связаны с причинами ее возникновения. Если высокий парный коэффициент корреляции отражает действительную взаимосвязь переменных, то для устранения мультиколлинеарности один из факторов не должен рассматриваться. Когда мультиколлинеарны факторы, играющие решающую роль в анализе, то отказ от них нежелателен. В этом случае можно использовать различные процедуры дополнительной обработки информации, например переход от исходных данных к их индексам, проведение дополнительного сбора и анализа данных, характеризующих явление, и т. п.
Явление мультиколлинеарности может быть обусловлено весьма специфичными причинами. При поиске корреляционных зависимостей почти всегда существует вероятность получения в той или иной степени ложных результатов. Очень часто большая мультиколлинеарность, возникающая при обработке экономической информации, вызвана именно ложной корреляцией между исследуемыми факторами. Такая мультиколлинеарность также ложна. По определению Н. С. Четверикова [48], «сущность ложной корреляции коренится в логических ошибках, совершаемых при неправильном пользовании методом корреляции или неправильном построении исследуемых единиц и их совокупностей». Выделяется пять групп источников ложной корреляции, в том числе возникновение ложной корреляции, выражающееся в получении высоких парных коэффициентов корреляции, неизбежное при исследовании тесноты связи между показателями, заданными динамическими рядами. Мультиколлинеарность, возникающая в таких случаях, является ложной временной мультиколлинеарностью, так как она происходит в результате применения метода корреляционного анализа к данным, не удовлетворяющим основным предпосылкам метода. Устранение мультиколлинеарности представляет весьма сложную задачу.
Другая проблема, которую приходится решать для экзогенных переменных, заключается в оценке значений факторов в прогнозируемом периоде. В классической теории прогнозирования каждый прогноз обусловлен значениями факторов в период Т. Поэтому ищутся такие значения переменной Ут, которые составляют «лучший» в определенном смысле прогноз. За ошибку прогноза принимаются только такие отклонения фактических значений Уу от расчетных, которые происходят при точном предсказании факторов.
Классические модели не дают ответа на вопрос, что можно ожидать, если факторы принимают иные значения1: Поэтому в моделях причинно-следственных связей приходится делать несколько прогнозов, соответствующих различным допущениям о формировании значений факторов*. Такой подход позволяет оценить чувствительность прогнозов к различным допущениям и построить множество возможных значений эндогенной переменной, соответствующих различным комбинациям значений факторов. Так как в этом случае каждый индивидуальный прогноз можно рассматривать как реализацию случайного процесса, полученное множество является случайным. Для его обработки следует применять аппарат исследования случайных процессов и выделять наиболее достоверный точечный или интервальный прогноз.
Можно наметить четыре способа задания значений экзогенных переменных в прогнозируемом периоде: на основе значений, принимаемых в соответствующих планах; экстраполяция фактических динамических рядов значений факторов; использование моделей причинно- следственных связей для оценки формирования отдельных факторов; на основе известного закона распределения значений факторов в прогнозируемом периоде.
*Функция распределения вероятностей для многомерного распределения не всегда принимает наибольшее значение в точке, координаты которой равны модам отдельных факторов. Это соответствует случаю, когда отдельные факторы являются независимыми.
Первый способ часто используется в практике прогнозирования, когда эндогенная переменная зависит от факторов, которые являются непосредственным показателем планирования. Например, для норм расхода топлива и энергии такими факторами будут объемы и структура производства. Они определяются с достаточно высокой степенью точности на прогнозируемый период.Второй способ наиболее приемлем, когда тренды факторов явно выражены, а отклонения от них незначительны. Экстраполяцию трендов следует использовать прежде всего в моделях, содержащих факторы, отражающие уровень развития техники и технологии производства, социально-экономические и природные условия. Например, отраслевая норма расхода топлива на выплавку Чугуна зависит от таких факторов, как средний объем доменных печей, доля агломерата и окатышей в шихте, степень обогащения дутья кислородом, расход природного газа, температура дутья и т. п. Процедура экстраполяции тенденции является весьма распространенной, так как с ней связано относительно мало дополнительных условий.
Третий способ характерен для ситуаций, когда имеются модели, описывающие поведение отдельных факторов. Использование этих моделей, особенно при прогнозировании на более отдаленные периоды времени, может оказаться весьма продуктивным.
Суть четвертого способа в том, что в расчетах принимаются значения факторов, при которых л-мерная функция распределения вероятностей достигает максимального значения*. В качестве прогноза принимаются значения, которые в условиях располагаемой информации представляются наиболее правдоподобными.
*Некоторые методы адаптивного прогнозирования автоматически предусматривают такую корреляцию.
Стабильность структурных параметров модели во времени означает, что структура описываемых моделью явлений и существующих между ними взаимосвязей остается постоянной, т. е. сохраняются неизменными аналитический вид модели и ее параметры. Стабильность рассматривается на отрезке времени, включающем вдВРервал, на котором была взята начальная выборка, и период прогноза.Требование стабильности параметров во времени является весьма «жестким», так как в действительности взаимосвязи между экономическими явлениями не остаются постоянными. С другой стороны, математико-статистические модели строятся на фактической информации, относящейся к прошлому, и поэтому являются прежде всего отражением прошлого. Такая ситуация наиболее характерна для моделей, основанных на динамических рядах, а не на пространственной выборке. Можно выделить три причины, вызывающие регулярные изменения структуры явления: технический прогресс; изменения в методах экономического управления; изменения и соотношениях экономических подмножестве, образующих агрегат высшего порядка.
Математическое прогнозирование на длительные интервалы связано с большими ошибками, так как допущение об относительной незначительности структурных изменений в будущем мало реально2.
Классическая теория математического прогнозирования основана прежде всего на стабильности структурных параметров модели во времени. Развитие методов математической статистики позволяет в настоящее время оценить стабильность модели, направление и величину происходящих изменений в параметрах [49]. Существует возможность предвидения изменений структурных параметров и учета их в прогнозе путем построения дополнительных прогнозирующих функций для соответствующей корректировки этих параметров. Тем самым удаётся расширить период прогнозирования и повысить точность расчетов.
Стабильность распределения случайного члена играет большую роль в построении достоверных прогнозов. Математико-статистические модели прогнозирования имеют стохастическую природу, т. е. эндогенные переменные являются случайными величинами, зависящими прежде всего от распределений случайного члена. Именно существование случайного члена определяет ошибку прогноза, т. е. отклонение фактического значения Ут от расчетного. Влияние случайного члена обусловлено его дисперсией. В частности, если коэффициент случайности (т. е. отношение среднеквадратичного отклонения случайного члена к среднему значению эндогенной переменной) велик, то это может не дать достаточно точной оценки параметров модели, а следовательно, и построения разумных прогнозов.
1 Известно, что соответствующий макропараметр является средневзвешенной величиной макропараметров нижележащего подмножества, причем весами являются доли участия подмножеств в макромножестве. Это обстоятельство широко используется в процессах экономического агрегирования, см. например, [50].
* Период прогнозирования, для которого можно допустить сохранение стабильности структуры, нельзя определить формально. Длительность интервала прогнозирования зависит от специфики исследуемого явления. Так, в технически быстро прогрессирующих отраслях структурные изменения происходят весьма часто. Тем самым здесь значительно сокращается допустимый период применения модели расчета потребности в топливе и энергии.
В некоторых ситуациях может наблюдаться рост случайного члена во времени, что характеризует увеличение степени отклонения фактических значений эндогенной переменной от ее расчетных значений, получаемых по модели. Это соответствует снижению точности прогнозирования при увеличении горизонта прогнозов. В этом случае точность прогнозов может быть повышена за счет введения специальных поправок на ожидаемое значение случайного члена в прогнозируемом периоде.
В ряде случаев наблюдается высокая автокорреляция значений случайного члена. Тогда метод наименьших квадратов, наиболее часто используемый для идентификации параметров математико-статистических моделей, дает несмещенные и состоятельные оценки, однако не обязательно вполне эффективные. Формулы для расчета стандартной ошибки и уровня существенности в этом случае оказываются неприемлемыми даже для приблизительных расчетов. Однако при прогнозировании правильное использование автокорреляции может способствовать повышению достоверности прогнозов. Это следует из возможности и допустимости прогнозирования значений случайного члена, когда известны фактические разности в предшествующем периоде*.
*В качестве критерия допустимости может быть выбран, например, показатель средней ошибки прогнозирования. Тогда горизонт прогноза определяется моментом Т*, так что Ът, (YT ) = р, где
Р — заданная точность прогноза.
В моделях прогнозирования принимается важное допущение относительно стабильности распределения во времени случайного члена. Если изменение распределения случайного члена во времени происходит довольно медленно и носит регулярный характер, то возможно проведение оценки зависимости дисперсии случайного члена от времени и экстраполяции этой функции на прогнозируемый период. Это позволяет соответственно корректировать прогнозы с целью повышения качества прогнозирования.
Допустимость экстраполяции модели за пределы выборки является одним из сложных положений прогнозирования. Этот вопрос не имеет иного эмпирического решения, чем взятие другой выборки, содержащей большее количество наблюдений, что часто практически оказывается невозможным. В результате допустимость экстраполяции обычно приходится обосновывать интуитивными предположениями.
Риск бескритичной экстраполяции модели заключается в априорном допущении о сохранении моделью своего аналитического вида за пределами выборки. Если выборка была малой, что часто имеет место в экономических расчетах, то вероятность неправильного использования модели прогнозирования существенно увеличивается. Наличие трендов у большинства экономических показателей также затрудняет обоснование допустимости экстраполяции модели, так как для прогнозируемого периода значения факторов могут быть иными, чем те, которые использованы при идентификации модели.
Оценка эффективности выбранных моделей прогнозирования наиболее часто основана на расчете ошибки прогноза. При этом следует различать расчетные и фактические показатели эффективности. Расчетные показатели характеризуют возможную среднюю ошибку, получаемую при определенном методе прогнозирования еще до реализации самого прогноза. Фактические показатели указывают действительную среднюю ошибку, имевшую место при использовании модели прогнозирования в течение некоторого периода времени.
В общем виде вычисление средней ошибки прогнозирования производится по следующей формуле:
где YT — фактическое значение эндогенной переменной в момент прогноза T;YT — расчетное значение, полученное по модели прогнозирования.
Средняя ошибка прогноза показывает, на сколько в среднем будут отличаться фактические значения от расчетных при большом числе прогнозов. В случае несмещенного прогноза средняя ошибка показывает возможную ошибку практических расчетов.
При оценке эффективности моделей прогнозирования следует осторожно пользоваться такими общепризнанными критериями, как коэффициент множественной корреляции и среднеквадратичное отклонение случайного члена. Эти оба показателя характеризуют лишь выборку, на основании которой проведена идентификация структурных параметров модели, и не применимы к периоду прогнозирования. Кроме того, при малом числе наблюдений познавательная ценность коэффициентов корреляции значительно снижается. Это объясняется
тем, что при малой выборке и относительно большом числе параметров модели искусственно получается хорошее совпадение эмпирических и расчетных значений эндогенной переменной. На самом деле в этом случае, как правило, доверительные интервалы коэффициента оказываются настолько большими, что пользование им становится невозможным, а проверка на существенность по критерию Фишера — Снедекора дает отрицательный результат.
Оценка эффективности различных моделей прогнозирования возможна при многократном повторении прогнозов. Здесь известны два метода расчета: один из них предложен Г. Тейлом [43], другой — X. Волдом и А. Гаддом [51]. Оба метода основаны на оценке рассогласования пар величин (У,,Ут). Использование этих методов не только позволяет оценить действительное качество прогноза, но также указывает на характерные причины ошибок. Г. Тейл выделяет три причины: смещение прогноза, неэластичность метода, несоответствие направления изменений, принятых в модели и в действительности. Метод Волда—Гадда, кроме того, характеризует стабильность параметров модели во времени, что является важным фактором любого математико-статистического прогноза.
Оценка горизонта прогноза — это интервал времени {t0, to + m), в котором выполняются все основные положения теории прогнозирования и возможен выбор метода прогнозирования, дающего допустимые результаты*. Интервал времени всегда является ограниченным, так как происходящие структурные изменения и научно- технический прогресс рано или поздно приводят к искажению моделей. Следует критически оценивать возможность использования математико-статистических моделей для целей прогнозирования. Обычно отмечается, что модели прогнозирования могут применяться прежде всего для построения кратко- и среднесрочных прогнозов, т. е. на период не более пяти лет. Прогнозирование на более длительные периоды связано со значительным риском. Такие прогнозы могут давать большие отклонения от фактических значений, которые невозможно оценить заранее.
*Выбор исходного ряда и прогноза в этом примере взяты так, чтобы можно было сопоставить расчетные значения с фактическими для 1972—1975 гг.
Рассмотрим примеры применения методов прогнозирования для оценки потребности в топливе и энергии.Используя модели тенденций развития, определим, например, нормы расхода топлива на отпуск теплоты из котельной на основании известного ряда удельных расходов за прошлые годы. В качестве исходной выборки приняты данные за 1967—1972 гг.; требуется построить прогноз исследуемого процесса на три года вперед, т. е. до 1975 г.*.
В качестве прогнозирующих функций примем следующие простейшие модели тенденций развития: линейную у=а+Ы; квадратичную у=а+Ы+сР; гиперболическую у=а+ЬЦ\ показательную y=atb. Исходные данные и результаты расчетов приведены в табл. 6-1.
*Экономическая эффективность использования побочных энергетических ресурсов определяется только всходя из замыкающих затрат на топливо. Применение прейскурантных цен на топливо в этих расчетах не допускается,
Таблица 6-1Сравнение [результатов прогнозирования норм расхода условного топлива на отпуск теплоты из котельной по модели тенденций развития (кг/Гкал)
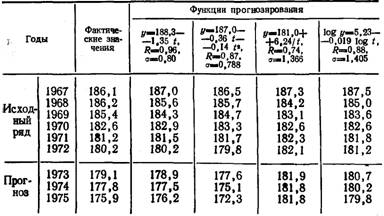
Примечание, у—функция прогнозирования; коэффициент корреляции; а—-среднеквадратичное отклонение.
Для выбора наиболее достоверного прогноза используем процедуру оценки по минимальному рассогласованию фактических и эмпирических значений в последнем моменте выборочного наблюдения. Применение этой процедуры приводит к выбору в качестве наилучшего прогноза результата, полученного по линейной функции. Правильность такого выбора подтверждает также сопоставление результатов прогноза с фактическими удельными расходами, наблюдаемыми в 1973—1975 гг. Здесь еще раз уместно подчеркнуть нецелесообразность применения для оценки наилучшего прогноза, в особенности в задачах краткосрочного прогнозирования таких показателей, как коэффициент корреляции R и среднеквадратичное отклонение а. Использование этих показателей привело бы к выбору квадратичной функции, которая в действительности дает несколько худшие результаты, чем линейная.
Т а б л и ц а 6*2
Динамика технико-экономических показателей доменного производства

Примечание. Значения отдельных факторов в прогнозируемом периоде определены по методу адаптивного прогнозирования временных рядов [521.
Сравнение результатов прогнозирования норм расхода сухого скипового кокса на выплавку чугуна по моделям причинно-следственных связей, кг/т
Уравнения регрессии (номер формулы) | Статистические характеристики уравнений | Прогнозные значения для лет ряда | |||
X | а | 11 | 12 | 13 | |
(6-5) | 0,998 | 6,283 | 555,7 | 546,9 | 541,1 |
(6-6) | 0,996 | 3,625 | 558,5 | 555,4 | 548,1 |
(6-7) | 0,999 | 3,429 | 560,2 | 557,2 | 556,0 |
(6-8) | 0,995 | 4,776 | 559,0 | 554,5 | 550,4 |
(6-12) | 0,985 | 6,890 | 557,2 | 549,7 | 541,2 |
Фактические |
|
| 558,0 | 549,7 | 542,4 |
Кроме моделей причинно-следственных связей, исследование проводилось по модели тенденций развития. Лучший результат был получен на показательной функции вида
log у=6,548—0,093 log t; i?=0,995; а=4,786. (6-8)
Основной недостаток всех отмеченных моделей, несмотря на высокую степень прогнозирующей способности, заключается в невозможности логического объяснения коэффициентов регрессии. Так, из практики известно, что увеличение значений принятых в модели факторов должно способствовать снижению удельного расхода кокса. Однако в полученных уравнениях некоторые факторы имеют знак «+», что противоречит логике и реальным физико-химическим закономерностям, составляющим существо процесса. Такое положение возникло в связи с ложной мультиколлинеарностью. По-видимому, можно считать (на основании многочисленных практических расчетов по моделям причинно-следственных связей), что для большинства экономических ситуаций, когда эндогенная переменная и экзогенные факторы заданы временными рядами, всегда имеет место явление ложной мультиколлинеарности. Применение обычных способов устранения или ослабления мультиколлинеарности в подобных ситуациях не дает ожидаемого эффекта. Об этом свидетельствует вид моделей (6-5)—(6-7).
Наиболее радикальным способом устранения ложной мультиколлинеарности является переход к моделям тенденций развития. При этом результаты оказываются тем лучше, чем ближе между собой тенденции развития отдельных факторов. Однако модели тенденций развития имеют ограниченное информационное содержание. Они не позволяют выделить и ранжировать по значимости факторы, определяющие поведение эндогенной переменной, что весьма важно при переходе от стадии планирования к реализации плана.
В результате возникает задача использования дополнительной информации, полученной за пределами рассматриваемых выборочных совокупностей, и ее учет при идентификации структурных параметров моделей причинно-следственных связей. В этих условиях обычный метод наименьших квадратов оказывается неприменимым.
Для подобных ситуаций созданы специальные разновидности метода наименьших квадратов, позволяющие учитывать дополнительные условия, например, в виде ограничений на сумму некоторых структурных параметров, их предельных значений и т. п. Однако эти разновидности метода не позволяют установить направления отдельных факторов, т. е. знаки при структурных параметрах. Для преодоления этого можно рассматривать схему идентификации структурных параметров модели, основанную на задаче квадратичного программирования. Тогда проблема сводится к решению следующей задачи: найти значения структурных параметров модели при факторах Х{, при которых сумма квадратов отклонений фактических значений от эмпирической линии регрессии достигает минимального значения:
![]() (6-9)
(6-9)
при ограничивающих условиях вида:
(6-10)
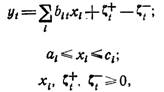 (6-11)
(6-11)
где yt — фактические значения эндогенной переменной в момент t; b,t — фактическое значение экзогенного фактора i в момент /; С ", С]- — соответственно положительные и отрицательные отклонения фактических значений эндогенной переменной от эмпирического значения, определяемого моделью; щ, Ci — дополнительные ограничения значения искомого структурного параметра Xi.
Этот подход был использован для рассмотренного выше примера прогнозирования удельного расхода кокса на выплавку чугуна. Полученная модель имела вид:
0 =1823,963—10,66*!—0,235 (346,734) (2,324) (0,151)
/?=985; а=6,89. (6-12)
Как видно из табл. 6-3, прогнозирование по модели (6-12) дало хорошие результаты при полной объясни- мости влияния отдельных факторов. Устойчивость коэффициентов регрессии получалась гораздо выше за счет исключения ряда незначимых факторов.
Целесообразность применения методов прогнозирования для расчета потребности в топливе и энергии достаточно очевидна. Особое внимание при этом следует уделять построению корректных математико-статистических моделей, обеспечивающих получение достоверных прогнозов.
Применение методов матричного исчисления при определении потребности предприятия в топ пиве и энергии позволяет получить эффективный и надежный инструмент расчета.
Этот метод является весьма полезным в условиях многономенклатурного производства и позволяет рассчитывать затраты на каждый вид готовой продукции.